.png)



Artificial Intelligence (AI) has brought transformative changes across professional fields. However, while the capabilities of models like OpenAI's Generative Pre-trained Transformer (ChatGPT) are undeniably impressive, their limitations become apparent in specialized sectors like law. As we stand at the intersection of legal practice and AI, it's clear that a shift in approach should occur. Our focus must transition from general large language models to domain-specific Large Legal Language Models (LLLMs).
The Limitations of ChatGPT in Legal Applications
ChatGPT, although adept at understanding and generating text, confronts several challenges in the nuanced field of law.
1. Privacy and Confidentiality: ChatGPT lacks built-in measures to ensure data privacy, a critical concern in law, where the protection of client information is essential.
2. Restricted Contextual Understanding: ChatGPT's limited context window can lead to the loss of vital information during extensive, complex legal discussions.
3. Infeasibility of Personalized Fine-Tuning: ChatGPT's broad scope makes it impractical to fine-tune it based on individual client data for personalized legal advice due to privacy and scalability issues.
4. Hallucination : ChatGPT can generate plausible but unverified or incorrect information, known as 'hallucination.'
5.Lack of Source Attribution: chatGPT is not designed to cite sources, making it challenging to validate the information it provides—a critical requirement in legal practice.
Advancing Legal AI with Large Legal Language Models
Given these challenges, it's clear that the future of legal AI demands a more specialized solution: Large Legal Language Models (LLLMs).
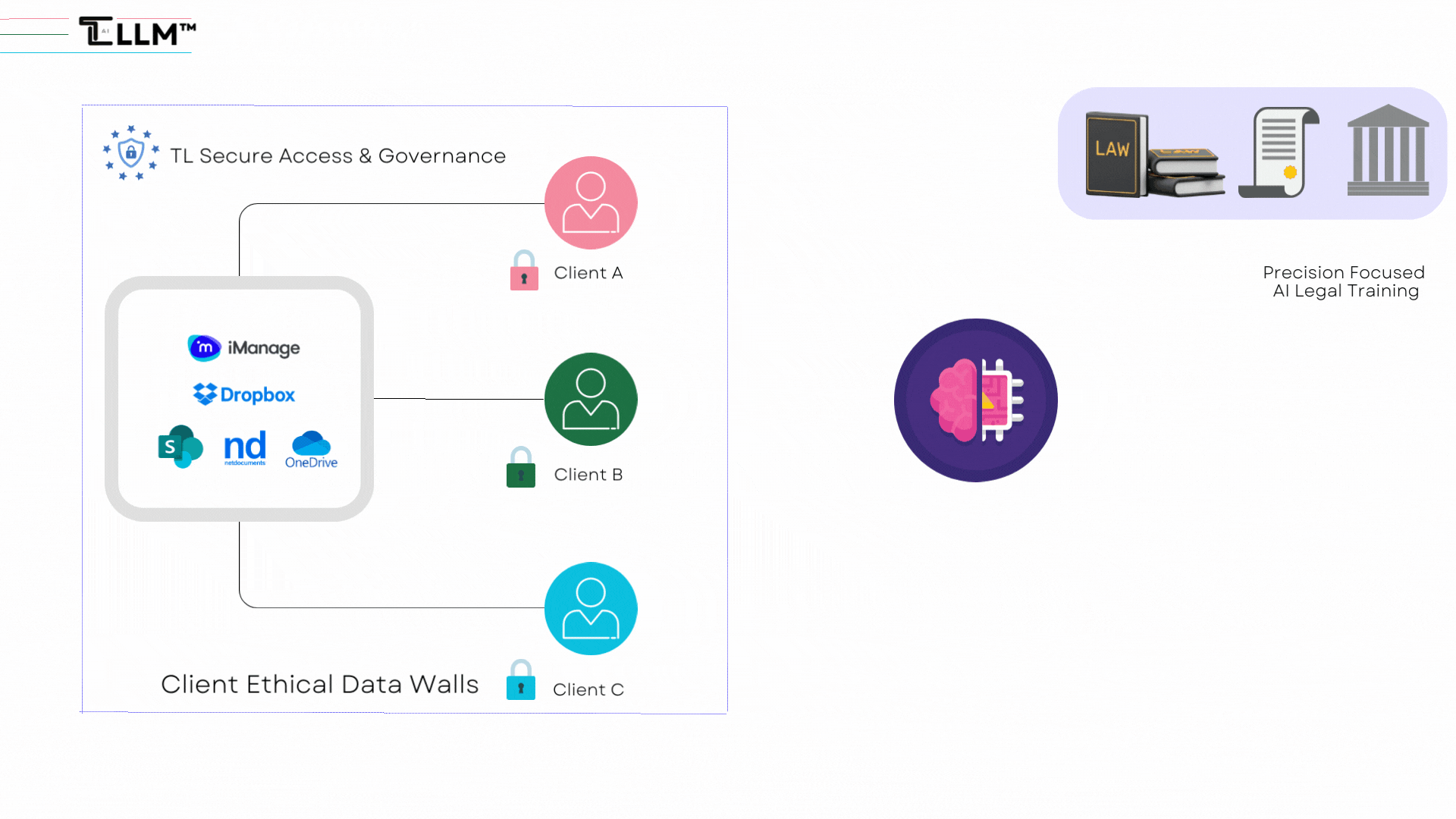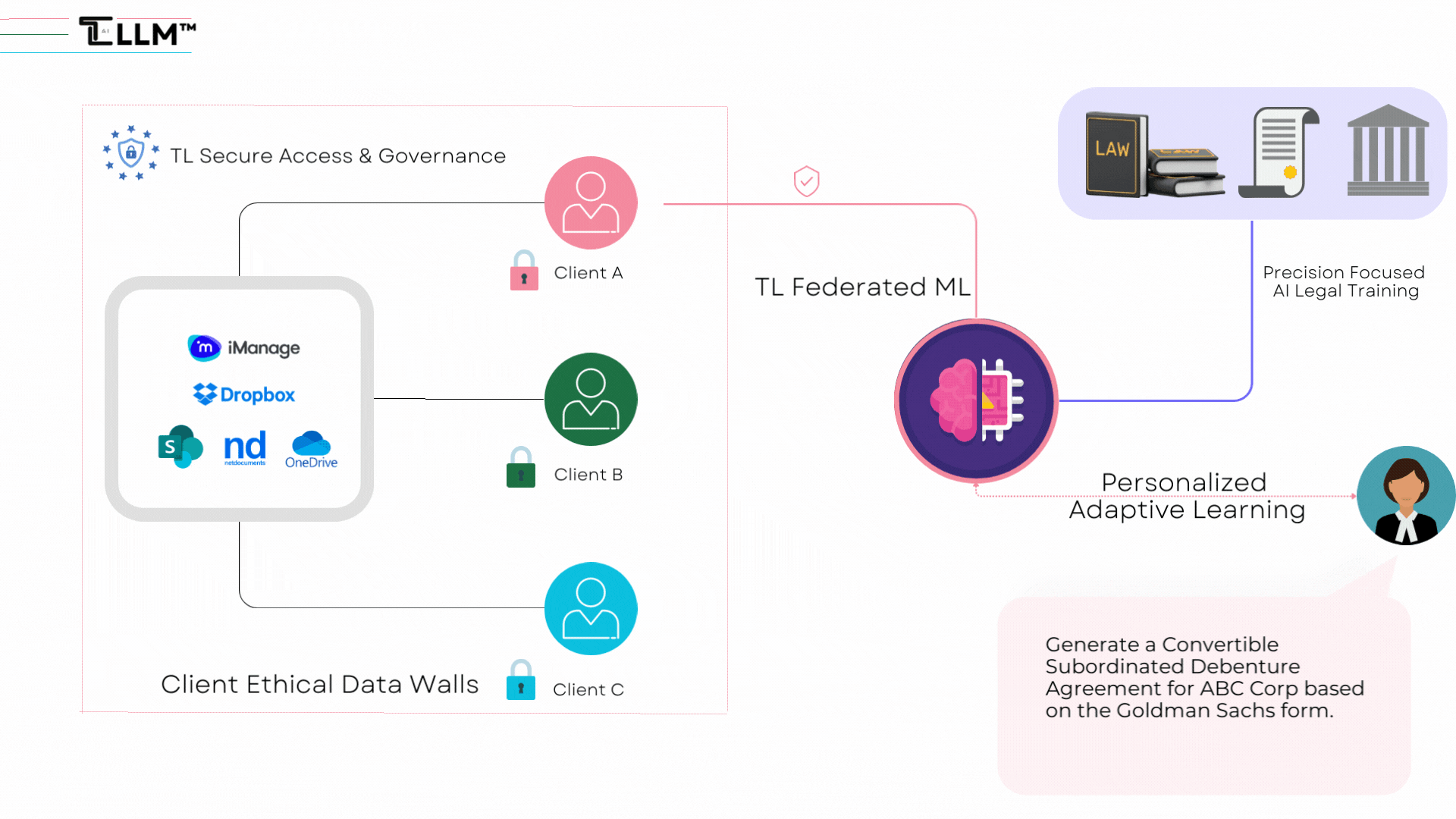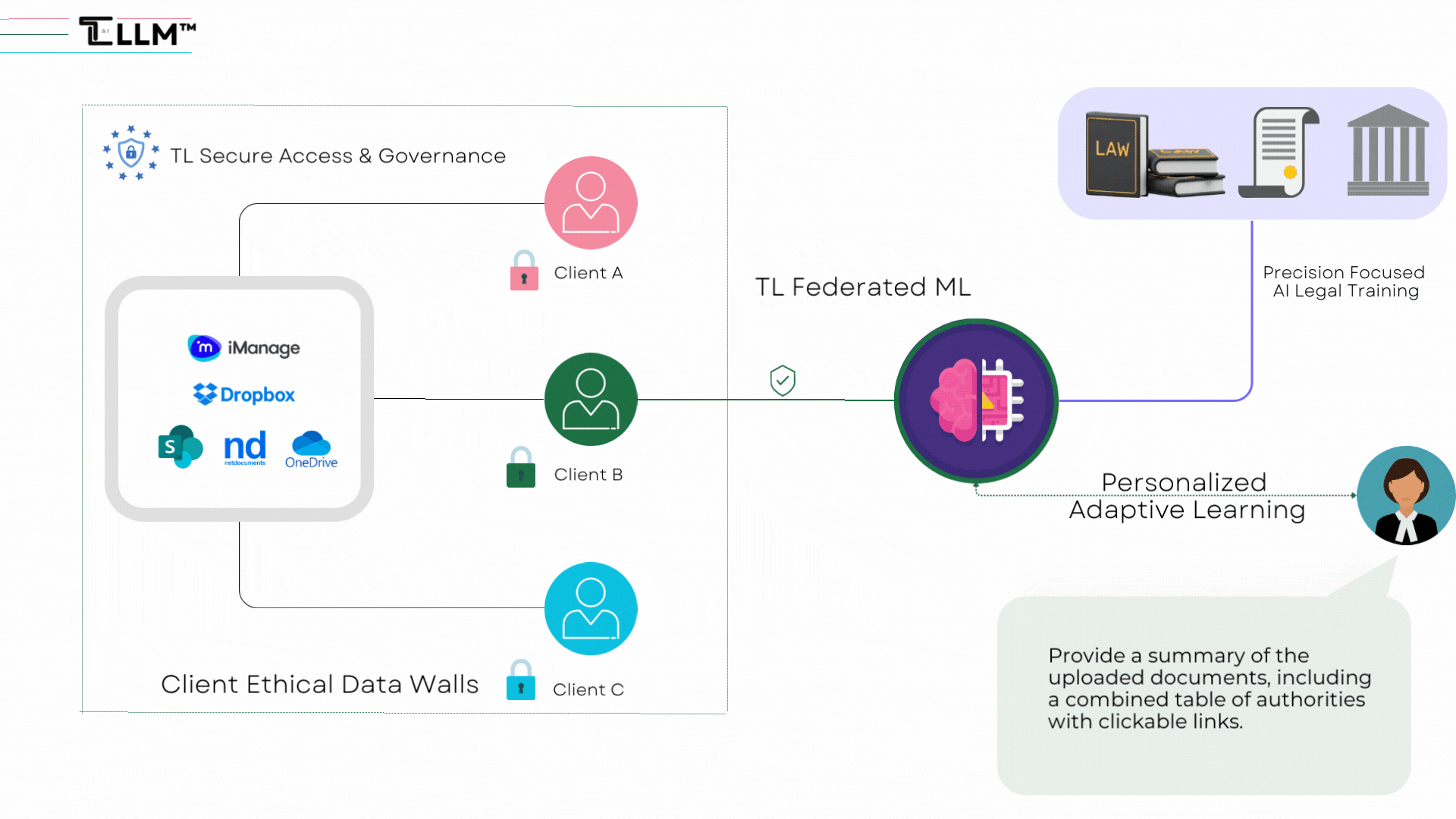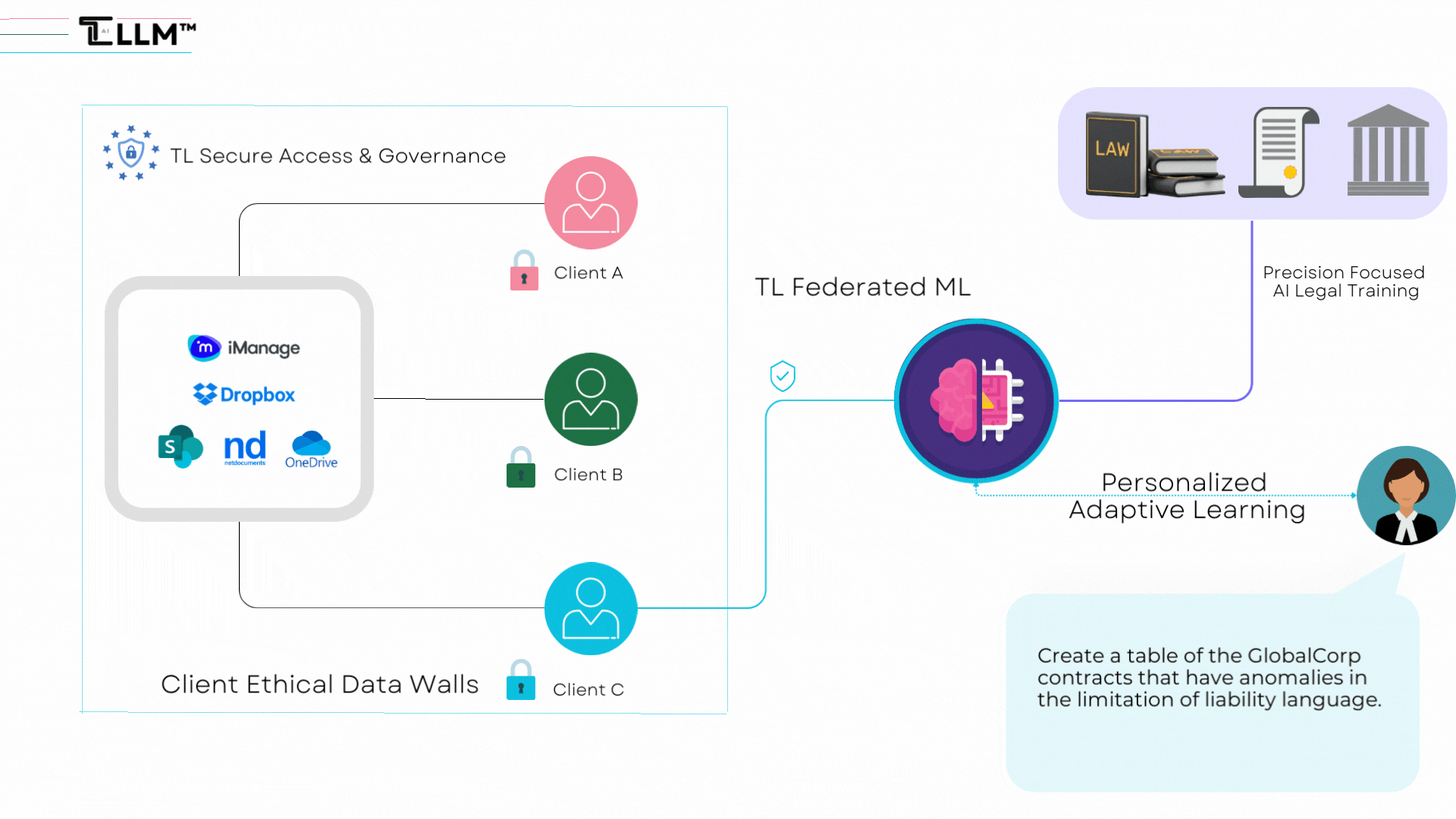
1. Robust Privacy Safeguards: LLLMs should be designed with strong privacy measures to protect sensitive client information. Techniques like local data processing and secure handling of interactions should be implemented to meet these needs.
2. Enhanced Contextual Understanding: Unlike ChatGPT, LLLMs should hold a larger context window or securely store important details, ensuring seamless continuity in legal discussions.
3. Domain-Specific Fine-Tuning: LLLMs should be developed to allow fine-tuning within specific legal areas, enhancing their adaptability and capacity to provide personalized legal advice while maintaining privacy standards.
4. Building Ethical Walls: LLLMs should be designed with the ethical norms of the legal profession in mind, ensuring transparency, accountability, and creating "ethical walls" to preserve client confidentiality and data privacy.
5. Client-Centric Approach: The development of LLLMs should be guided by a strong client-first principle. This encompasses two key factors:
- Data Handling: With explicit client consent, LLLMs should securely incorporate client-specific data, ensuring not only accuracy but also tailored legal assistance that truly meets each client's unique needs.
- User Experience: To optimize client interaction and satisfaction, the user interface of LLLMs should be intuitive and user-friendly. This will enable clients to navigate and use these models more effectively, enhancing their overall experience and satisfaction.
6. Reducing Hallucination: LLLMs should be meticulously designed to mitigate the risk of hallucination. Hallucination, or the generation of plausible but inaccurate or unverified information, is a notable concern with large language models. Rigorous testing and iterative refinement are vital in this regard to ensure the model's responses are not just persuasive but also reliable and factual.
7. Source Attribution: To boost credibility and allow for validation of the information provided, LLLMs should ideally include a feature for source attribution. Training these models on a corpus of verified legal texts, court judgments, laws, and legal opinions could provide the basis for this feature, enhancing the trust users place in the generated responses.
The shift to LLLMs represents a significant change: from models that only understand and generate language to those skilled in "legal language." LLLMs are not simply scaled up versions of existing tech for the legal industry. Instead, they are a new type of AI tool designed specifically to understand and respect the unique requirements and complexities of the legal field.
- LLLMs protect client data by using techniques such as differential privacy, federated learning. By capturing a broader context and retaining important details, they provide more accurate and contextually relevant responses, improving the overall quality of legal advice and support.
- LLLMs can be customized to specific legal areas, enhancing their expertise in different branches of law. They can operate within ethical norms and professional standards by establishing clear boundaries and safeguards, instilling trust and confidence in both legal practitioners and clients.
- LLLMs can offer personalized legal advice tailored to each client's unique circumstances, fostering a stronger lawyer-client relationship. By incorporating accurate and reliable sources, they provide more trustworthy and verifiable legal insights.
- The development and implementation of LLLMs present challenges, including robust data privacy measures, ethical considerations, and fine-tuning complexities. Collaboration between legal experts, AI researchers, and ethicists is crucial to ensure that LLLMs are developed, deployed, and utilized in a responsible and ethical manner.
In summary, LLLMs represent a pivotal moment in legal AI. By harnessing the 'legal' aspect in these models, we can overcome the limitations of general language models, propelling the legal industry towards a more efficient, accurate, and client-centric future.


.png)