



In the ever-evolving landscape of legal technology, e-discovery stands out as a domain ripe for innovation. With the rise of large language models (LLMs) like GPT-4, the ability to sift through vast amounts of legal data has been revolutionized. However, the deployment of such models often involves significant resource expenditure and complexity. This is where the technique of model distillation steps in as a game-changer, especially for law firms looking to harness AI more efficiently and effectively.
What is Model Distillation?
Model distillation is a training approach where a smaller, more efficient model (known as the "student") is taught to emulate the behavior of a larger, more powerful model (the "teacher"). This process not only makes the student model faster and less resource-intensive but often allows it to match or even exceed the teacher model's performance on specific tasks.
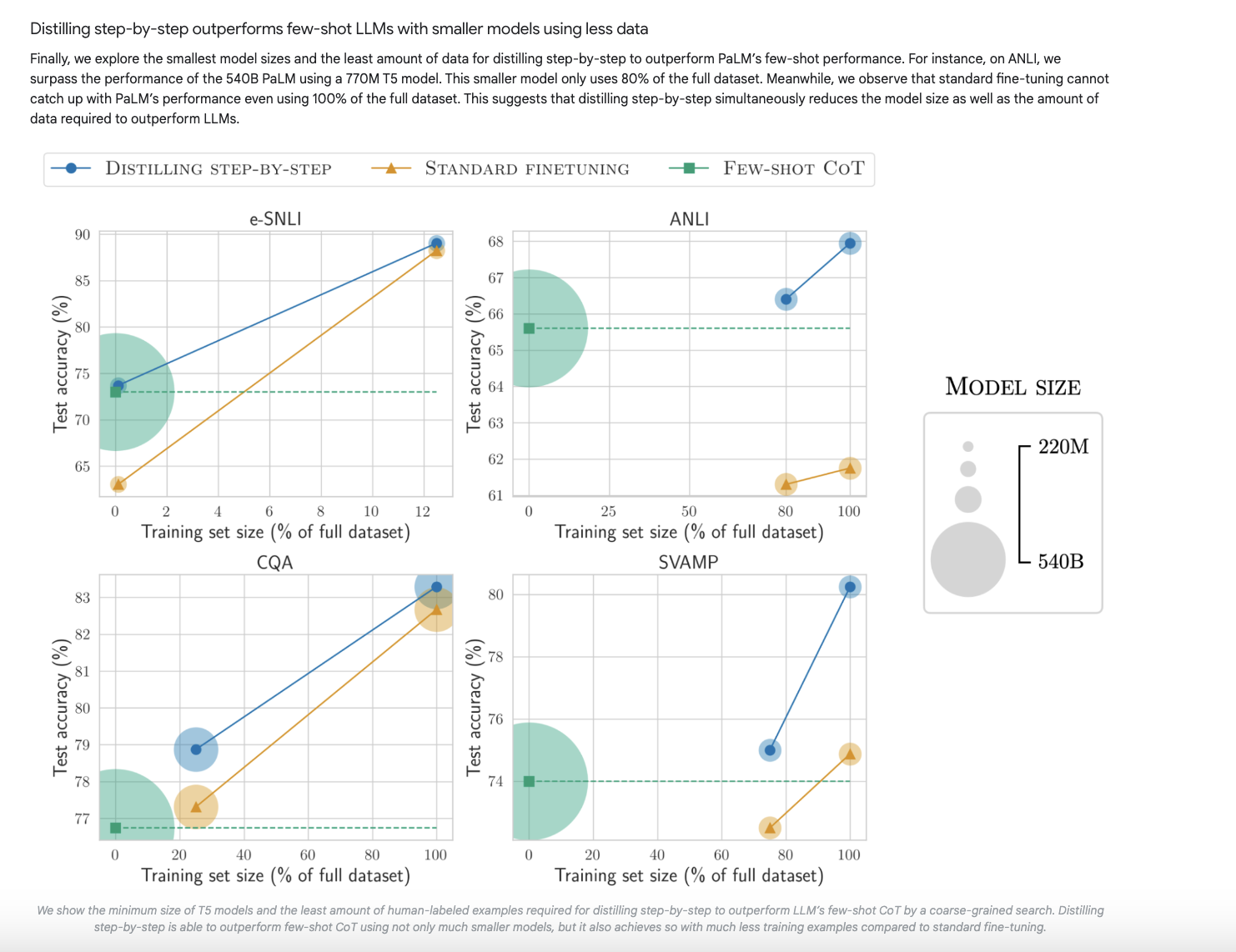
The Case for Distillation in e-Discovery
For e-discovery, the benefits of model distillation are manifold:
- Cost Efficiency: Distilled models require significantly less computational power and storage, translating into lower operational costs.
- Speed: Smaller models yield faster data processing, crucial for time-sensitive legal proceedings.
- Customization: Distillation facilitates the creation of custom models tailored to a firm’s specific legal playbook and expertise. This customization can lead to improvements in the model's precision and recall, making them more effective than general-purpose LLMs.
Building Case-Specific LLMs
In e-discovery, each legal case or project can involve unique sets of documents and specific legal questions. Traditional LLMs, while powerful, are not inherently tuned for the nuances of every individual case. Distilled models, however, can be specifically trained using data and outcomes from similar past cases handled by the firm. This training approach not only makes these models adept at understanding context-specific nuances but also integrates a firm’s specific legal strategies and decision-making processes.
Enhancing Precision and Recall
One of the most significant advantages of using distilled models in e-discovery is their ability to offer improved precision and recall rates. By training these models on case-specific datasets, they are not only familiar with the type of language and format of relevant documents but also with the legal relevance of the content. Such targeted training helps in reducing false positives and negatives, ensuring that the model retrieves more accurate and relevant documents.
Conclusion
Distillation opens up new avenues for law firms to not only save on costs and operational overhead but also to enhance the effectiveness of their e-discovery processes. By developing custom, case-specific LLMs, firms can leverage AI to deliver precise, reliable legal document analysis tailored to their unique needs. As legal professionals continue to embrace AI, distillation stands out as a potent tool in the legal tech toolkit, offering both performance and efficiency without the typical constraints of larger models.
This approach not only ensures that firms stay at the cutting edge of technology but also maintain their competitive edge in a data-driven legal environment.


.png)